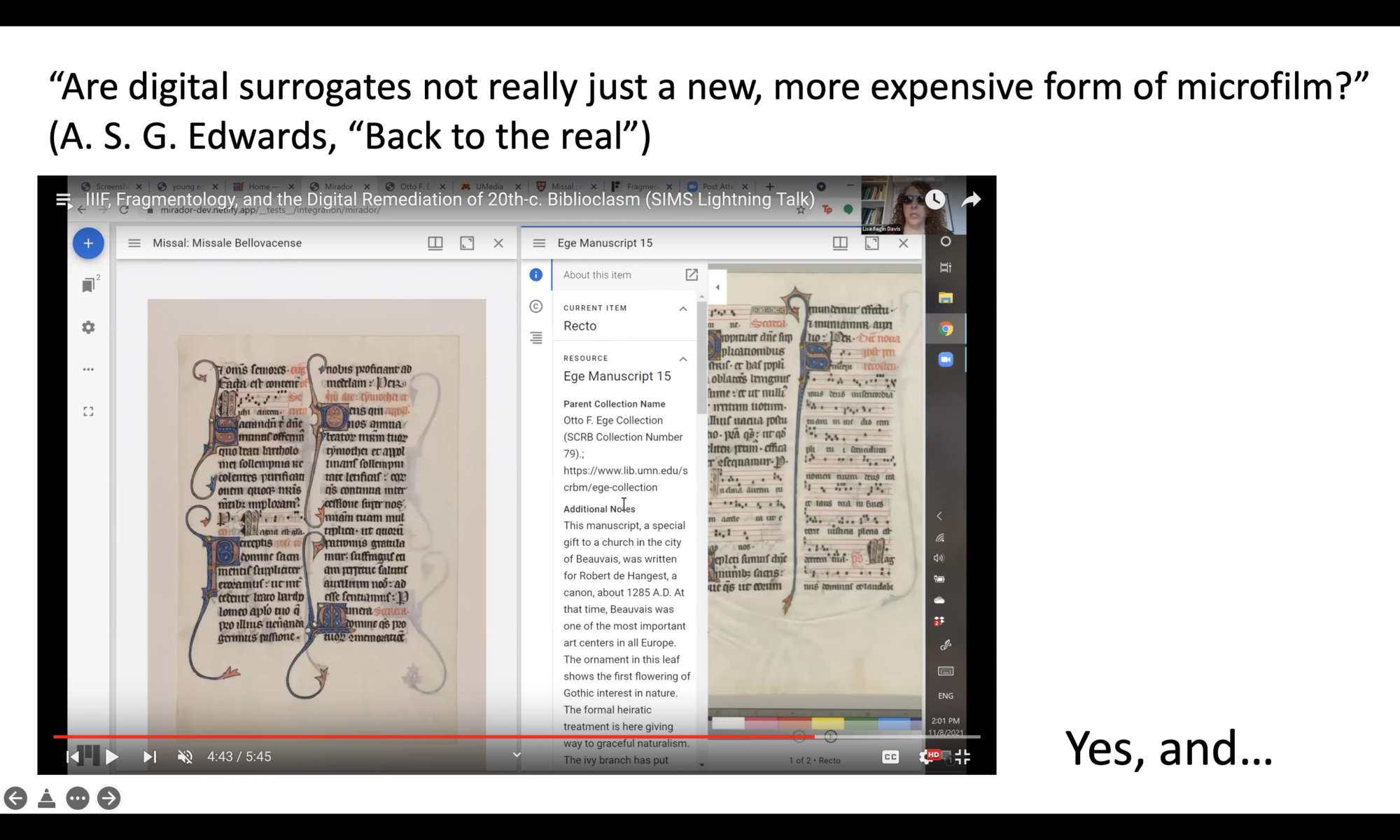
Originally presented at the 14th Annual Schoenberg Symposium on Manuscript Studies in the Digital Age, November 17, 2021
Continue reading “Manuscript Loss in Digital Contexts”Manuscript Loss in Digital Contexts

Development in production
Originally presented at the 14th Annual Schoenberg Symposium on Manuscript Studies in the Digital Age, November 17, 2021
Continue reading “Manuscript Loss in Digital Contexts”
This post is a summary of a Mellon Seminar I presented at the Price Lab for Digital Humanities at the University of Pennsylvania on February 19th, 2018. I will be presenting an expanded version of this talk at the Rare Book School in Philadelphia, PA, on June 12th, 2018
Continue reading “Ceci n’est pas un manuscrit: Summary of Mellon Seminar, February 19th 2018”
This week I participated in a workshop organized by the Collections as Data project at the annual meeting of the American Historical Association in Washington, DC. The session was organized by Stewart Varner and Laurie Allen, who introduced the session, and the other participants were Clifford Anderson and Alex Galarza.
Continue reading “Slides from OPenn Demo at the American Historical Association Meeting”So you’ve just digitized medieval manuscripts from your collection and you’re putting them online. Congratulations! That’s great.
Continue reading ““Freely available online”: What I really want to know about your new digital manuscript collection”