

This post is a summary of a Mellon Seminar I presented at the Price Lab for Digital Humanities at the University of Pennsylvania on February 19th, 2018. I will be presenting an expanded version of this talk at the Rare Book School in Philadelphia, PA, on June 12th, 2018

In my talk for the Mellon Seminar I presented on three of my current projects, talked about what we gain and lose through digitization, and made a valiant attempt to relate my talk to the theme of the seminars for this semester, which is music and sound. (The page for the Mellon Seminars is here, although it only shows upcoming seminars.) I’m not sure how well that went, but I tried!
I started my talk by pointing out that medieval manuscripts are physical objects – sometimes very large objects! They have weight and size and heft, and unlike static objects like sculptures, manuscripts move. They need to move in order for us to read them. But digitized manuscripts – the ones you find for example in Penn in Hand, the page-turning interface for Penn’s digitized manuscript collection – don’t really move. Sure, we have an interface that gives the impression of turning the pages of the book, but those images are flat, static files that are just the latest version in a long history of facsimile copies of manuscripts. A page-turning interface for medieval manuscripts is the equivalent of taking a book, cutting the pages out, and then pasting those pages into a photo album. You can read the pages but you lose the sense of the book as a physical object.
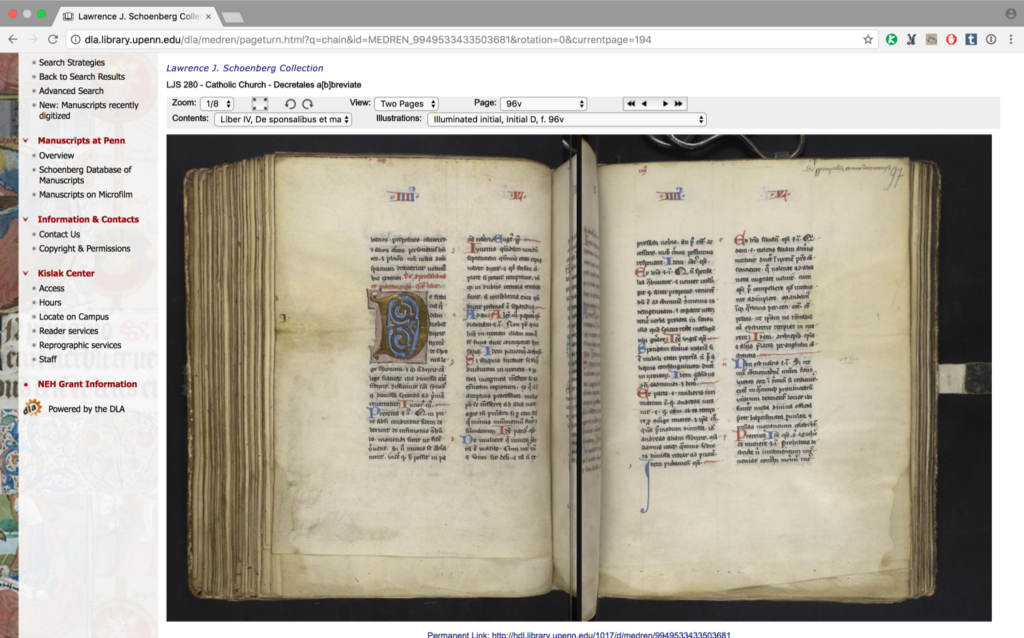
It sounds like I’m complaining, but I’m really not. I like that digital photographs of manuscripts are readily available and relatively standard, but I do think it’s vitally important that people using them are aware of how they’re different from the “real” manuscript. So in my talk I spent some time deconstructing a screenshot from a manuscript in Penn in Hand (see above). It presents itself as a manuscript opening (that is, two facing pages), but it should be immediately apparent that this is a fake. This isn’t the opening in the book, it’s two photos placed side-by-side to give the impression of the opening of the book. There is a dark line down the center of the window which clearly delineates the photo on the left and the one on the right. You can see two gutters – the book only has one, of course, but each photo includes it – and you can also see a bit of the text on the facing page in each photo. From the way the text is angled you can tell that this book was not laid flat when it was photographed – it was held at or near a 90 degree angle (and here’s another lie – the impression that the page-turning interface gives us is that of a book laid flat. Very few manuscripts lay flat. So many lies!).
We can see in the left-hand photo the line of the edge of the glass, to the right of the gutter and just to the left of the black line. In our digitization lab we use a table with a spring-loaded top and a glass plate that lays down on the page to hold it flat. (You can see a two-part demo of the table on Facebook, Part One and Part Two) This means the photographer will always know where to focus the camera (that is, at the level of the glass plate), and as each page of the book is turned the pages are the same distance from the camera (hence the spring under the table top). I think it’s also important to know that when you’re looking at an opening in a digital manuscript, the two photos in that composite view were not taken one after the other; they were possibly taken hours apart. In SCETI, the digitization lab in the Penn Libraries, all the rectos (that is, the front of the page) are taken at one time, and then the versos (the back of the page) are taken, and then the system interleaves them. (For an excellent description of digital photography of books and issues around it please see Dr. Sarah Werner’s Pforzheimer Lecture at the Harry Ransom Center on Early Digital Facsimiles)
I moved from talking about how digital images served through page-turning interfaces provide one kind of mediated (~fake~) view of manuscripts to one of my ongoing projects that provides another kind of mediated (also fake?) view of manuscripts: video. I could talk and write for a long time about manuscript videos, and I am trying to summarize my talk and not present it in full, so I’ll just say that one advantage that videos have over digitized images is that they do give an impression of the “real” manuscript: the size of them, the way they move (Is it stiff? How far can it open? Is the binding loose or tight?), and – relevant to the Seminar theme! – how they sound. I didn’t really think about it when I started making the videos four years ago, but if you listen carefully in any of the videos you can hear the pages (and in some cases the bindings), and if you listen to several of them you can really tell the difference between how different types of parchment and paper sound. Our complete YouTube playlist of video orientations is here, but I’ll embed one of my favorites here. This is LJS 280, a 13th century copy of Decretales Gregorii IX in a 15th century chain binding that makes a lot of noise.
I don’t want to imply that videos are better than digital images – they just tell us something that digital images can’t. And digital images are useful in ways that videos aren’t. For one thing, if you’re watching a video you can see the way the book moves, but I’m the one moving it. It’s still a mediated experience, it’s just mediated in a different way. You can see how it moved at a specific time, in a specific situation, with a specific person. If you want to see folio 45v, you’re out of luck, because I didn’t turn to that page (and even if I had, the video resolution might not be high enough for you to read it; the video isn’t for reading – that’s why we have the digital images).
There’s another problem with videos.

In four years of the video orientation program, we have 74 videos online. We could have more if we made it a higher priority (and arguably we should), but each one takes time: for research, to set up and take down equipment, for the recording (sometimes multiple takes), and then for the processing. The videos are also part of the official record of the manuscript (we load them into the library’s institutional repository and link them to records in the library’s catalog) and doing that means additional work.
At this point I left videos behind and went back to digital images, but a specific project: Bibliotheca Philadelphiensis, which we call BiblioPhilly. BiblioPhilly is a major collaborative project to digitize medieval manuscripts from institutions across Philadelphia, organized by the Philadelphia Area Consortium of Special Collections Libraries (PACSCL) and funded by the Council on Library and Information Resources (CLIR). We’re just entering year three of a three-year grant, and when we’re done we’ll have 476 manuscripts online (we have around 130 online now). If you’re interested in checking out the manuscripts that are online, and to see what’s coming, you can visit our search and browse site here.
The relevance of BiblioPhilly in my talk is that we’re being experimental with the kind of data we’re creating in the cataloging work, and with how we use that data to provide new and different manuscript views.
Manuscript catalogers traditionally examine and describe the physical structure of the codex. Codex manuscripts start as sheets of parchment or paper, which are stacked and folded to create booklets called quires. Quires are then gathered together and sewn together to make a text block, then that is bound to make the codex. So describing the physical structure means answering a few questions: How many quires? How many leaves in each quire? Are there leaves that are missing? Are there leaves that are singletons (i.e., were never part of a sheet)? When a cataloger has answered these questions they traditionally describe the structure using a collation formula. The formula will list the quires, number of leaves in a quire, and any variations. For example, a manuscript with 10 quires, all of which have eight leaves except for quire six which has four, and there are some missing leaves, might have a formula like this:
1-4(8), 5(8, -4,5), 6(4), 7-10(8)
(Quires 1 through 4 have eight leaves, quire 5 had eight leaves but four and five are now missing, quire 6 has four leaves, and quires 7-10 have eight leaves)
The formula is standardized for printed books, but not for manuscripts.
Using tools developed through the research project VisColl, which is designing a data model and system for describing and visualizing the physical construction of manuscripts, we’re building models for the manuscripts as part of the BiblioPhilly cataloging process, and then using those models to generate the formulas that go into our records. This itself is good, but once we have models we can use them to visualize the manuscripts in other ways too. So if you go to the BiblioPhilly search and browse site and peek into the records, you’ll find that some of them include links to a “Collation View”

Following that link will take you to a page where you can see diagrams showing each quire, and image files organized to show how the leaves are physically connected through the quire (that is, the sheets that were originally bound together to form the quire).

Like the page-turning interface, this is giving us a false impression of what it would be like to deconstruct the manuscript and view it in a different way, but like the video is it also giving us a view of the manuscript that is based in some way on its physicality.
And this is where my talk ended. We had a really excellent question and answer session, which included a question about why I don’t wear gloves in the videos (my favorite question, which I answer here with a link to this blog post at the British Library) but also a lot of great discussion about why we digitize, and how, and why it matters, and how we can do it best.
Thanks so much to Glenda Goodman and Stewart Varner for inviting me, and to everyone who showed up.