Originally presented at the 14th Annual Schoenberg Symposium on Manuscript Studies in the Digital Age, November 17, 2021
Continue reading “Manuscript Loss in Digital Contexts”Manuscript Loss in Digital Contexts
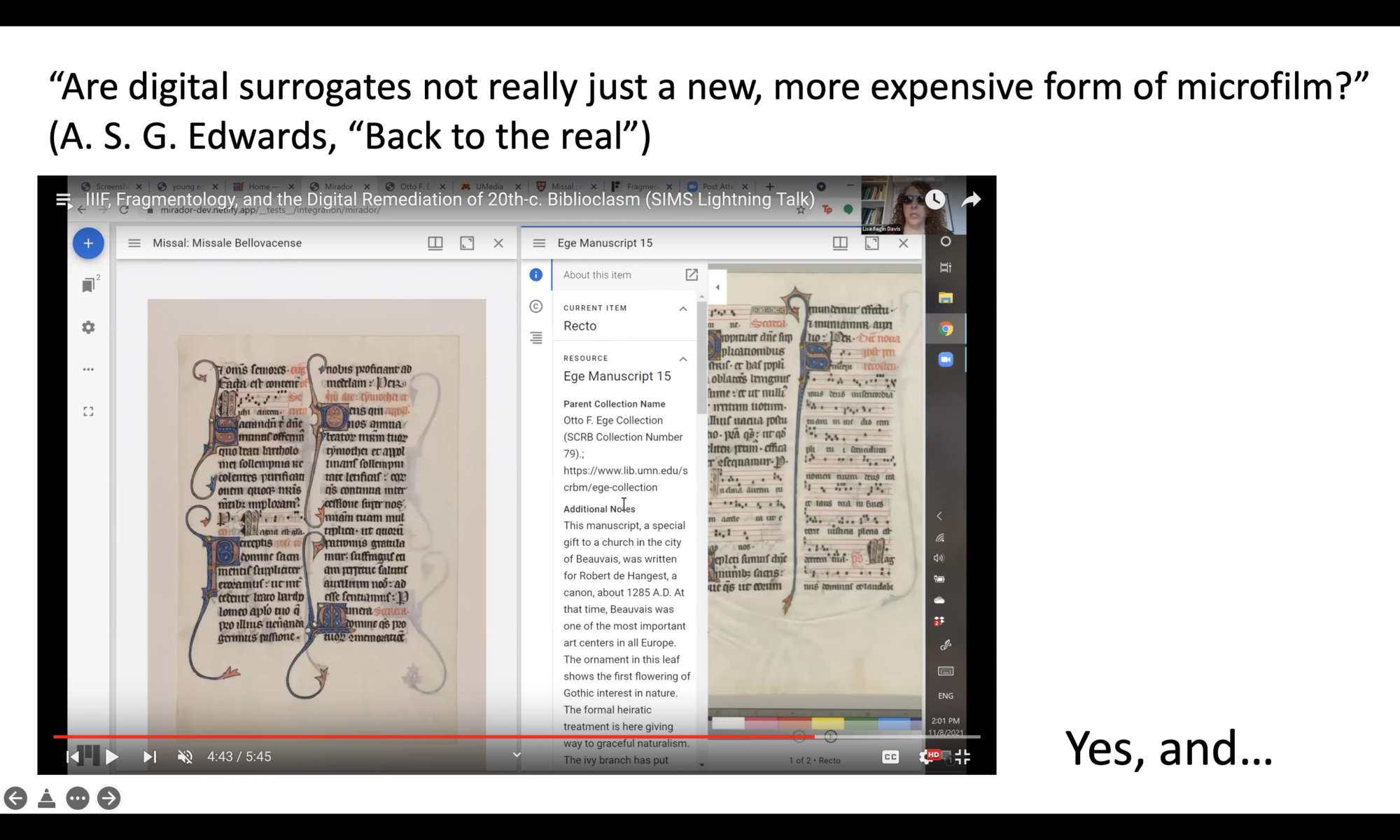

Development in production
Originally presented at the 14th Annual Schoenberg Symposium on Manuscript Studies in the Digital Age, November 17, 2021
Continue reading “Manuscript Loss in Digital Contexts”
This is a version of a paper I presented as a Rare Book School Lecture at the University of Pennsylvania in Philadelphia on June 12, 2018, originally entitled “Is this your book? What digitization does to manuscripts and what we can do about it.”
Continue reading “Is This Your Book? What we call digitized manuscripts and why it matters”
This is a version of a paper presented at the International Congress on Medieval Studies, May 12, 2018, in session 482, Digital Skin II: ‘Franken-Manuscripts’ and ‘Zombie Books’: Digital Manuscript Interfaces and Sensory Engagement, sponsored by Information Studies (HATII), Univ. of Glasgow, and organized by Dr. Johanna Green.
Continue reading “Zombie Manuscripts: Digital Facsimiles in the Uncanny Valley”
This is the full text of a talk I presented at the Parker on the Web 2.0 Symposium in Cambridge on March 16, 2018 (Please note addendum at the end which addresses an issue that came up in discussion later in the day.)
Continue reading “Using VisColl to Visualize Parker on the Web: Reports on an experiment”
This post is a summary of a Mellon Seminar I presented at the Price Lab for Digital Humanities at the University of Pennsylvania on February 19th, 2018. I will be presenting an expanded version of this talk at the Rare Book School in Philadelphia, PA, on June 12th, 2018
Continue reading “Ceci n’est pas un manuscrit: Summary of Mellon Seminar, February 19th 2018”
The text of a lightning talk originally presented at The Futures of Medieval Historiography, a conference at the University of Pennsylvania organized by Jackie Burek and Emily Steiner. Keep in mind that this was very lightly researched; please be kind.
Continue reading “The Historiography of Medieval Manuscripts in England (and the USA)”