
Hi everyone! It’s been almost a year since my last blog post (in which I promised to post more frequently, haha) so I guess it’s time for another one. I actually have something pretty interesting to report!
Last week I gave an invited talk at the Cultural Heritage at Scale symposium at Vanderbilt University. It was amazing. I spoke on OPenn: Primary Digital Resources Available to Everyone, which is the platform we use in the Schoenberg Institute for Manuscript Studies at the University of Pennsylvania Libraries to publish high-resolution digital images and accompanying metadata for all our medieval manuscripts (I also talked for a few minutes about the Schoenberg Database of Manuscripts, which is a provenance database of pre-1600 manuscripts). The philosophy of OPenn is centered on openness: all our manuscript images are in the public domain and our metadata is licensed with Creative Commons licenses, and none of those licenses prohibit commercial use. Next to openness, we embrace simplicity. There is no search facility or fancy interface to the data. The images and metadata files are on a file system (similar to the file systems on your own computer) and browse pages for each manuscript are presented in HTML that is processed directly from the metadata file. (Metadata files are in TEI/XML using the manuscript description element)
This approach is actually pretty novel. Librarians and faculty scholars alike love their interfaces! And, indeed, after my talk someone came up to me and said, “I’m a humanities faculty member, and I don’t want to have to download files. I just want to see the manuscripts. So why don’t you make them available as PDF so I can use them like that?”
This gave me the opportunity to talk about what OPenn is, and what it isn’t (something I didn’t have time to do in my talk). The humanities scholar who just wants to look at manuscripts is really not the audience for OPenn. If you want to search for and page through manuscripts, you can do that on Penn in Hand, our longstanding page-turning interface. OPenn is about data, and it’s about access. It isn’t for people who want to look at manuscripts, it’s for people who want to build things with manuscript data. So it wouldn’t make sense for us to have PDFs on OPenn – that’s just not what it’s for.
HOWEVER. However. I’m sympathetic. Many, many people want to look at manuscripts, and PDFs are convenient, and I want to encourage them to see our manuscripts as available to them! So, even if Penn isn’t going to make PDFs available institutionally (at least, not yet – we may in the future), maybe this is something I could do myself. And since all our manuscript data is available on OPenn and licensed for reuse, there is no reason for me not to do it.
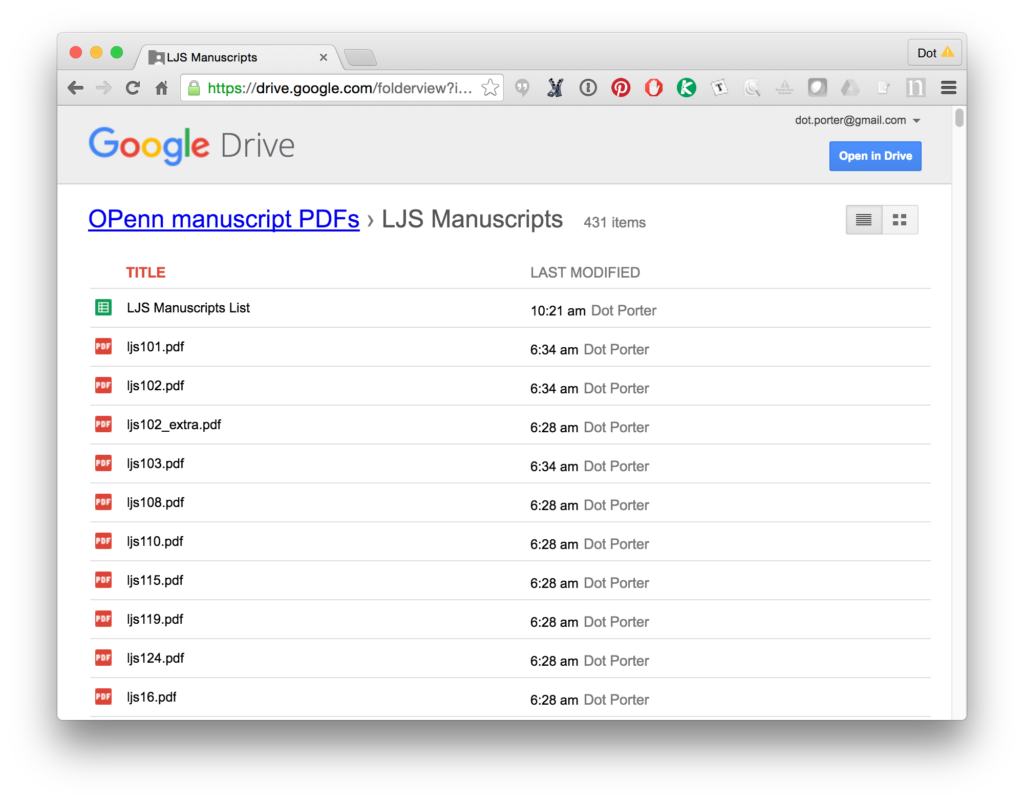
If you click that link, you’ll find yourself in a Google Drive folder titled “OPenn manuscript PDFs”. In there is currently one folder, “LJS Manuscripts.” In that folder you’ll fine a link to a Google spreadsheet and over 400 PDF files. The spreadsheet lists all the LJS manuscripts (LJS = Laurence J. Schoenberg, who gifted his manuscripts to Penn in 2012) including catalog descriptions, origin dates, origin locations, and shelfmarks. Let’s say you’re interested in manuscripts from France. You can highlight the Origin column and do a “Find” for “France.” It’s not a fancy search so you’ll have to write down the shelfmarks of the manuscripts as you find them, but it works. Once you know the shelfmarks, go back into the “LJS Manuscripts” folder and find and download the PDF files you want. Note that some manuscripts may have two PDF files, one with “_extra” in the file name. These are images that are included on OPenn but not part of the front-to-back digitization of a manuscript. They might include things like extra shots of the binding, or reference shots.
If you are interested in knowing how I did this, please read on. If not, enjoy the PDFs!
How I did it
I’ll be honest, this is my favorite part of the exercise so thank you for sticking with me for it! There won’t be a pop quiz at the end although if you want to try this out yourself you are most welcome to.
First I downloaded all the web jpeg files from the LJS collection on OPenn. I used wget to do this, because with wget I am able to get only the web jpeg files from all the collection folders at once. My wget command looked like this:
wget -r -np -A “_web.jpg” http://openn.library.upenn.edu/Data/0001/
Brief translation:
wget = use the wget program
-r = “recursive”, basically means go into all the child folders, not just the folder I’m pointing to
-np = “no parent”, basically means don’t go into the parent folders, no matter what
-A “_web.jpg” = “accept list”, in this case I specified that I only want those files that contain _web.jpg (which all the web jpeg files on OPenn do)
http://openn.library.upenn.edu/Data/0001/ = where all the LJS manuscript data lives
I didn’t use the -nd command, which I usually do (-nd = “no directory”, if you don’t use this command you get the entire file structure for the file server starting from root, which in this case is openn.library.upenn.edu. What this means, practically, is that if you use wget to download one file from a directory five levels up, you get empty folders four levels deep then the top director with one file in it. Not fun. But in this case it’s helpful, and you’ll see why later.
At my house, with a pretty good wireless connection, it took about 5 hours to download everything.
I used Automator to batch create the PDF files. After a bit of googling I found this post on batch creating multipage PDF files from jpeg files. There are some different suggestions, but I opted to use Mac’s Automator. There is a workflow linked from that post. I downloaded that and (because all of the folders of jpeg images I was going to process are in different parent folders) I replaced the first step in the workflow, which was Get Selected Finder Items, with Get Specified Finder Items. This allowed me to search in Automator for exactly what I wanted. So I added all the folders called “web” that were located in the ancestor folder “openn.library.upenn.edu” (which was created when I downloaded all the images from OPenn in the previous step). In this step Automator creates one PDF file named “output.pdf” for each manuscript in the same location as that manuscript’s web jpeg images (in a folder called web – which is important to know later).
Once I created the PDFs, I no longer needed the web jpeg files. So I took some time to delete all the web jpegs. I did this by searching in Finder for “_web.jpg” in openn.library.upenn.edu and then sending them all to Trash. This took ages, but when it was done the only thing in those folders were output.pdf files.
I still had more work to do. I needed to change the names of the PDF files so I would know which manuscripts they represented. Again, after a bit of Googling, I chanced upon this post which includes an AppleScript that did exactly what I needed: it renames files according to the path of their location on the file system. For example, the file “output.pdf” located in Macintosh HD/Users/dorp/Downloads/openn/openn.library.upenn.edu/Data/0001/ljs101/data/web would be renamed “Macintosh HD_Users_dorp_Downloads_openn_openn.library.upenn.edu_Data_0001_ljs101_data_web_001.pdf”. I’d never used AppleScript before so I had to figure that out, but once I did it was smooth sailing – just took a while. (To run the script I copied it into Apple’s Script Editor, hit the play button, and selected openn.library.upenn.edu/Data/0001 when it asked me where I wanted to point the script)
Finally, I had to remove all the extraneous pieces of the file names to leave just the shelfmark (or shelfmark + “extra” for those files that represent the extra images). Automator to the rescue again!
- Get Specified Finder Items (adding all PDF files located in the ancestor folder “http://openn.library.upenn.edu”)
- Rename Finder Items to replace text (replacing “Macintosh HD_Users_dorp_Downloads_openn_openn.library.upenn.edu_Data_0001_” with nothing) –
- Rename Finder Items to replace text (replacing “_data_web_001” with nothing)
- Rename Finder Items to replace text (replacing “_data_extra_web_001” with “_extra” – this identifies PDFs that are for “extra” images)
The last thing I had to do was to move them into Google Docs. Again, I just searched for “.pdf” in Finder (just taking those that are in openn.libraries.upenn.edu/Data/0001) and dragged them into Google Drive.
All done!
The spreadsheet I generated by running an XSLT script over the TEI manuscript descriptions (it’s a spreadsheet I created a couple of years ago when I first uploaded data about the Penn manuscripts on Viewshare. Leave a comment or send me a note if that sounds interesting and I’ll make a post on it.
I’d be interested to hear how you created the spreadsheet!
I’m glad you’re interested! I did it in XSLT, although you could probably use another language just as well (I use XSLT because it’s what I know). I’ve put a note in my calendar to make a quick post tomorrow about the spreadsheet so you can expect another post then.