
Following are my remarks from the Collections as Data National Forum 2 event held at the University of New Mexico, Las Vegas, on May 7 2018. Collections as Data is an Institute of Museum and Library Services supported effort that aims to foster a strategic approach to developing, describing, providing access to, and encouraging reuse of collections that support computationally-driven research and teaching in areas including but not limited to Digital Humanities, Public History, Digital History, data driven Journalism, Digital Social Science, and Digital Art History. The event was organized by Thomas Padilla, and I thank him for inviting me. It was a great event and I was honored to participate.
Today I’m going to be talking about curators as an audience for collections as data, using two projects from the University of Pennsylvania’s Kislak Center for Special Collections, Rare Books and Manuscripts as use cases. I am a curator in the Kislak Center, and most of my time I work on projects under the aegis of the Schoenberg Institute for Manuscript Studies, which is a unit under the Kislak Center. SIMS is a kind of research and development group (our director likes to refer to it as a think tank) that focuses on manuscript studies writ large, mostly but by no means only focused on medieval manuscripts from Europe, and that specializes in examining the relationship between manuscripts as physical objects and their digitized counterparts.
For this session, we’ve been asked to react to this assertion from the Collections as Data Santa Barbara Statement: Collections as data designed for everyone serve no one, and to discuss the audiences that our collections as data are built for.
I’ll start with OPenn, which launched in May 2015 as an open access collection of Penn’s digitized manuscript material. Penn started digitizing its manuscripts in the mid 1990s, but they had been virtually locked in a black box system. To create OPenn we cracked opened the box, generated new derivative images from the master TIFF files, generated TEI/XML manuscript description files using the data from our catalog and supporting databases, and put it all in a fully public file server. The collection navigation is provided by HTML pages – one that lists all the repositories, pages listing the manuscripts in each repository, and finally HTML pages for each manuscript presenting the catalog data and links to the image files. At the time OPenn launched, there was no search facility, although one has recently been added.
OPenn’s developer, Doug Emery, describes the access that OPenn provides as friction-free access, referring both to the licensing (the image files are in the public domain, the metadata is licensed cc:by) and to the technical access. There’s no login and no API. You can navigate to the site in a browser and download images, or you can point wget at the server and bulk download entire manuscripts.

When we were designing OPenn, we weren’t thinking that much about the audience, honestly. We were thinking about pushing the envelope with fully available, openly licensed, high resolution, robustly described and well-organized digitized medieval manuscripts. We did imagine who might use our collections, and how, and you can read the statement from our readme here on the screen.
But I can’t say that we built the system to serve any audience in particular. We did build the system in a way that we thought would be generally useful and usable. But it became clear after OPenn launched that our lack of an audience made it difficult for us to “sell” OPenn to any group of people. Medievalists, faculty and students, who might want to use the material, were put off by the relatively high technical learning curve, the simple interface (lacking the expected page-turning view) and by the lack of search (we do have a Google Search now, but it was only added to the site in the past month). Data analysts who might want to visualize the collection-wide data were put off by the formatting of each manuscript having its own TEI file. Indeed data designed for everyone does seem to serve no one.

But wait! Don’t lose hope! An accidental audience did present itself. In the months and into the first year after OPenn launched, it was slowly used as a source for projects. The Philadelphia Area Consortium of Special Collections Libraries, PACSCL, undertook a collaborative project whereby each member institution digitized five diaries from their collections, which were put on OPenn, the PACSCL Diaries Project.
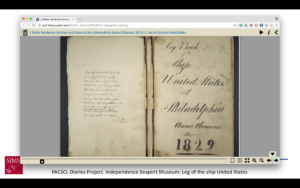 When the project went live, the folks at PACSCL wanted a user-friendly way to make the diaries available, so I generated page-turning interfaces using the Internet Archive Bookreader that pulled in metadata from the TEI files and that point to the image files served on OPenn.
When the project went live, the folks at PACSCL wanted a user-friendly way to make the diaries available, so I generated page-turning interfaces using the Internet Archive Bookreader that pulled in metadata from the TEI files and that point to the image files served on OPenn.
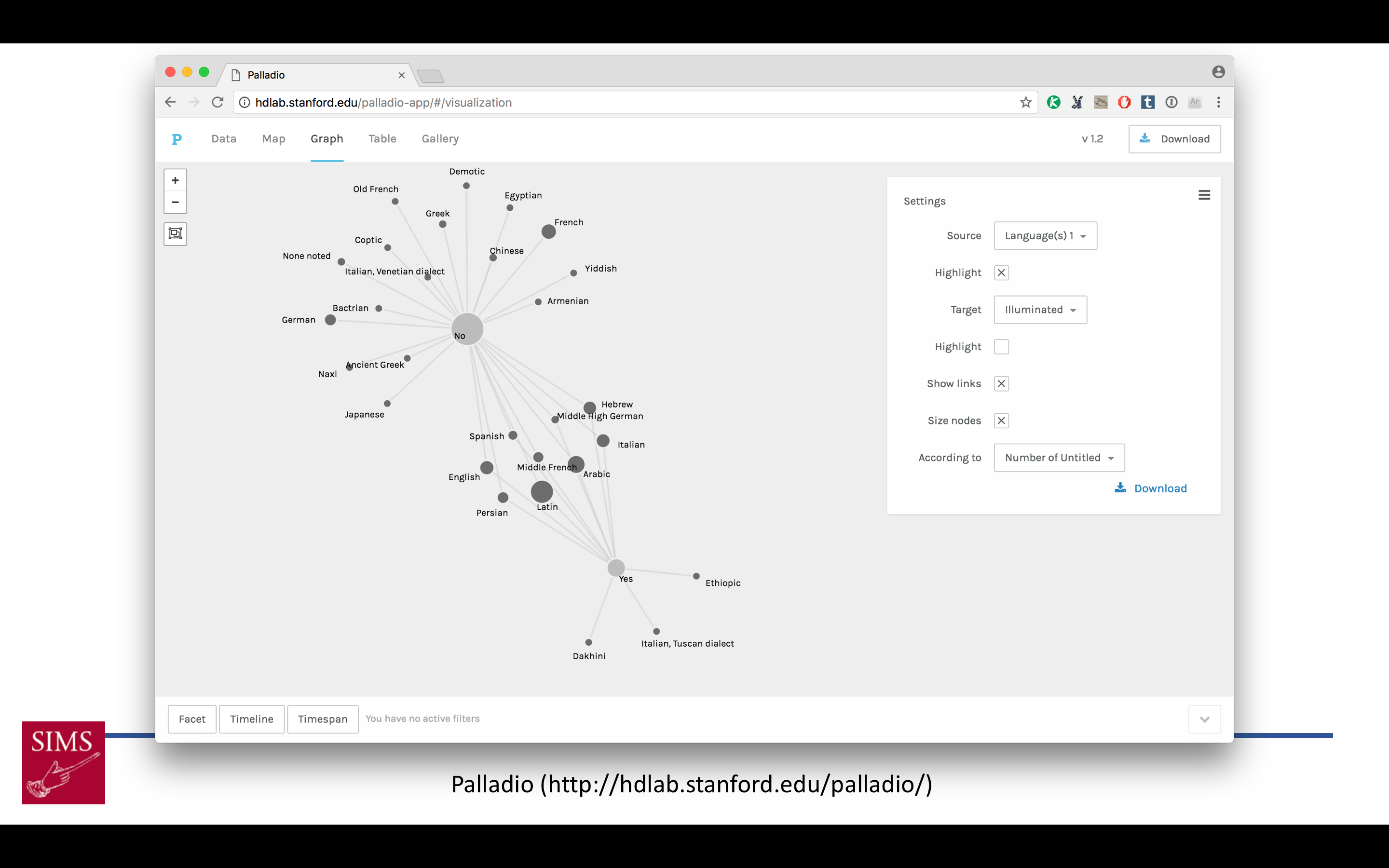 At some point I decided that I wanted to get a better sense of one of our manuscript collections, the Lawrence J. Schoenberg Collection, so again I wrote a script to generate a CSV file pulling from all the collection’s TEI files. Jessie Dummer, the Kislak Center’s Digitization Project Coordinator, cleaned up the data in the CSV, and we were able to load the CSV into Palladio for visualization and analysis (on github)
At some point I decided that I wanted to get a better sense of one of our manuscript collections, the Lawrence J. Schoenberg Collection, so again I wrote a script to generate a CSV file pulling from all the collection’s TEI files. Jessie Dummer, the Kislak Center’s Digitization Project Coordinator, cleaned up the data in the CSV, and we were able to load the CSV into Palladio for visualization and analysis (on github)
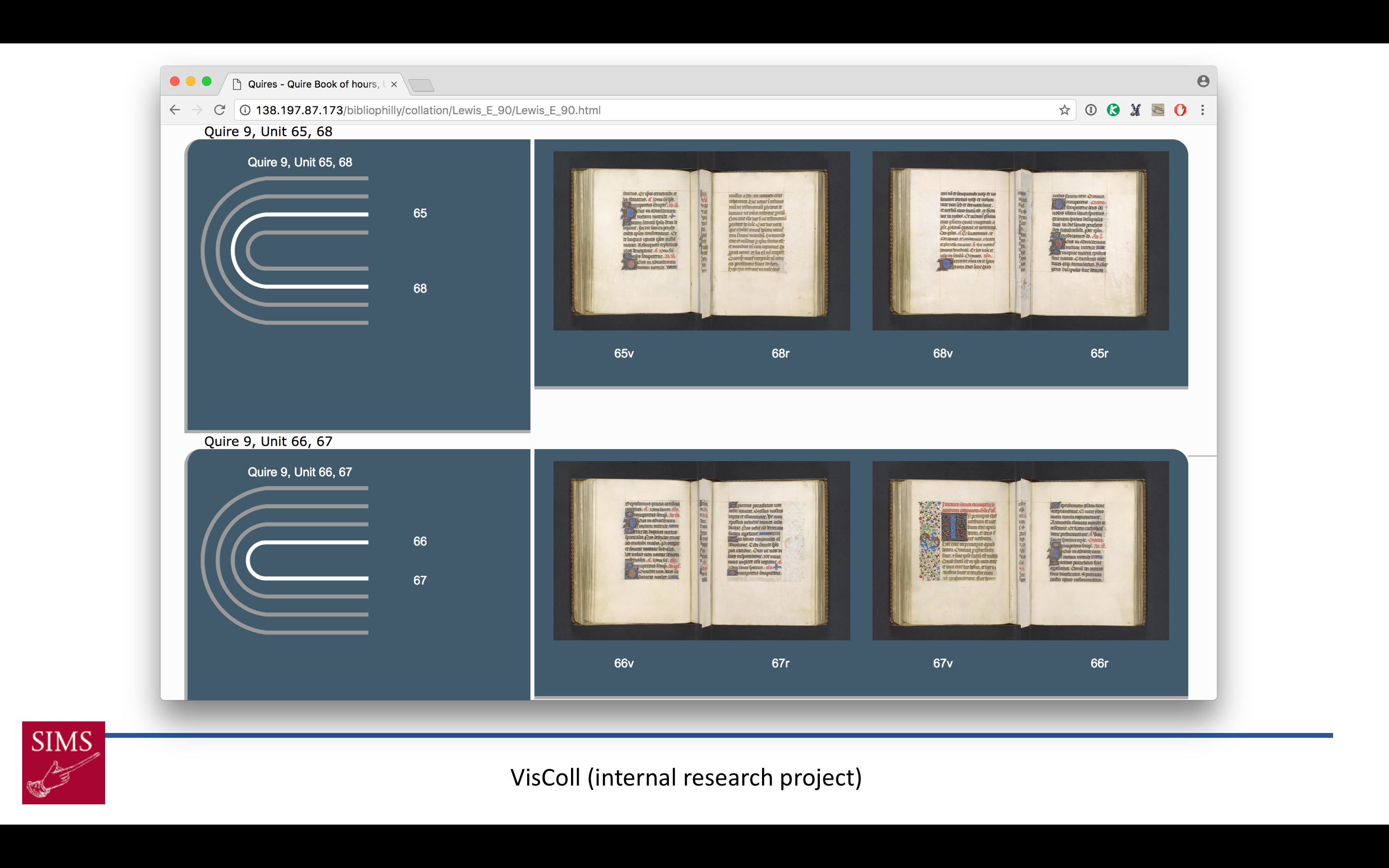 I combined the links to images on OPenn with data gathered through another SIMS project, VisColl (which I’ll describe in a bit more detail later) to generate a visualization of the gathering structure of manuscripts with the bifolia, or sheets, laid alongside.
I combined the links to images on OPenn with data gathered through another SIMS project, VisColl (which I’ll describe in a bit more detail later) to generate a visualization of the gathering structure of manuscripts with the bifolia, or sheets, laid alongside.  And last but not least, I experimented with setting up a IIIF image server that could serve the images from OPenn as IIIF-compatible images (this is a screenshot of the github site where I published IIIF manifests I generated as part of that project, but they don’t work because the server no longer exists).
And last but not least, I experimented with setting up a IIIF image server that could serve the images from OPenn as IIIF-compatible images (this is a screenshot of the github site where I published IIIF manifests I generated as part of that project, but they don’t work because the server no longer exists).
The accidental audience? It was me.
I don’t remember thinking about or discussing with the rest of the team as we planned for OPenn how I might use it as part of my regular work. I was familiar with the concept of an open collection of metadata and image files online; OPenn was based on The Digital Walters, which both the Director of the Kislak Center Will Noel and Doug Emery had built when they were employed at the Walters Art Museum in Baltimore, and I had been playing with that data for a year before I was even hired at Penn. I must have know that I would use it, I just didn’t realize how much I would use it, or how having it available to me would change the way I thought about my work, and the way I worked with the collections. The things that made it difficult for other people to use OPenn – the lack of a search facility, the dependence on XML – didn’t affect me negatively. I already knew the collection, so a search wasn’t necessary; at the time OPenn launched I had been working with XML technologies for 10 years or so, so I was very comfortable with it.
Having OPenn as a source for data gives me so much in my curatorial role. I have the flexibility to build the interfaces I want using tools I can understand, and flexibility, easy access, familiar formats
 At the very end of 2015, several months after OPenn was launched, we, along with PACSCL, Lehigh University, and the Free Library of Philadelphia, were awarded a grant from the Council on Library and Information Resources under the “Digitizing Hidden Collections” program to digitize western Medieval manuscripts in 15 Philadelphia area libraries. We call the project Bibliotheca Philadelphiensis, the “library of Philadelphia”, or BiblioPhilly for short. Working from my experience working with data on OPenn, during the six-month lead up to cataloging and digitization I was able to build the requirements for the BiblioPhilly metadata in a way to guarantee that the resulting data would be useful to me and to the curators and librarians at the other institutions. Some of the things we implemented include a closed list of keywords (based on the keyword list developed for the Digital Walters), in contrast with the Library of Congress subject headings in OPenn, and four different date fields (date range start, date range end, single date, and narrative date) with strict instructions for each (except for narrative date) to ensure that the dates will be computer readable.
At the very end of 2015, several months after OPenn was launched, we, along with PACSCL, Lehigh University, and the Free Library of Philadelphia, were awarded a grant from the Council on Library and Information Resources under the “Digitizing Hidden Collections” program to digitize western Medieval manuscripts in 15 Philadelphia area libraries. We call the project Bibliotheca Philadelphiensis, the “library of Philadelphia”, or BiblioPhilly for short. Working from my experience working with data on OPenn, during the six-month lead up to cataloging and digitization I was able to build the requirements for the BiblioPhilly metadata in a way to guarantee that the resulting data would be useful to me and to the curators and librarians at the other institutions. Some of the things we implemented include a closed list of keywords (based on the keyword list developed for the Digital Walters), in contrast with the Library of Congress subject headings in OPenn, and four different date fields (date range start, date range end, single date, and narrative date) with strict instructions for each (except for narrative date) to ensure that the dates will be computer readable.
 We have also integrated data from VisColl into BiblioPhilly, both into the data itself, and in combination with the data in the interfaces. VisColl, as I mentioned before, is a system to model and visualize the quire structure of manuscripts. (A manuscript’s quire structure is called its collation, hence the name VisColl – visualizing collation) VisColl models are XML files that describe each leaf in a manuscript and how those leaves relate to each other (if they are in the same quire, or if they are conjoined, if a leaf is missing or has been added, etc.). From a model we’re able to generate a concise description of a manuscripts’ construction, in a format referred to as a collation formula, and this formula is included in the manuscript’s cataloging and becomes part of the TEI manuscript description. However we’re also able to combine the information from the collation model with the links to the image files on OPenn to generate views of a collation diagram alongside the sheets that make up the quires.
We have also integrated data from VisColl into BiblioPhilly, both into the data itself, and in combination with the data in the interfaces. VisColl, as I mentioned before, is a system to model and visualize the quire structure of manuscripts. (A manuscript’s quire structure is called its collation, hence the name VisColl – visualizing collation) VisColl models are XML files that describe each leaf in a manuscript and how those leaves relate to each other (if they are in the same quire, or if they are conjoined, if a leaf is missing or has been added, etc.). From a model we’re able to generate a concise description of a manuscripts’ construction, in a format referred to as a collation formula, and this formula is included in the manuscript’s cataloging and becomes part of the TEI manuscript description. However we’re also able to combine the information from the collation model with the links to the image files on OPenn to generate views of a collation diagram alongside the sheets that make up the quires.
For BiblioPhilly, because of the experimentation we did with Penn manuscripts on OPenn, we’ve been able to make the digitized BiblioPhilly manuscripts available online in ways that are more user-friendly to non-technical users than OPenn is, even before we have an “official” project interface. We did this by building an In Progress Viewer relatively early on. The aim of the In Progress viewer was 1) to provide technically simple, user-friendly ways to search, browse, and view the manuscripts, and 2) to make available information both about the manuscripts that were online, and about the manuscripts that had yet to go online (including the date they were photographed, so users can track manuscripts of particular interest through the process).
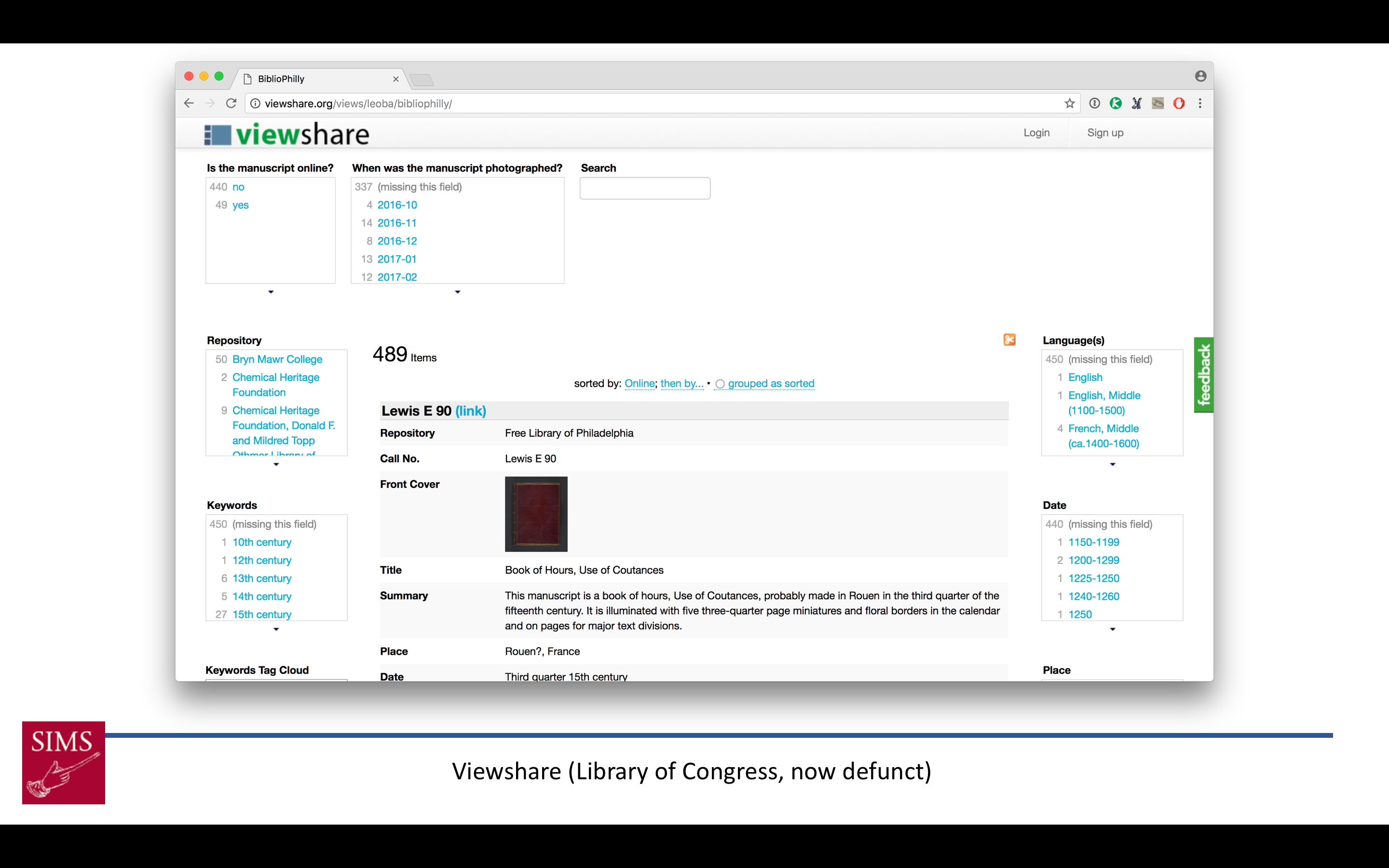 The first In Progress Viewer was built in the Library of Congress’s Viewshare, which provided federated browsing for all the fields in our records, along with a timeline and simple mapping facility. Unfortunately the Library of Congress is no longer supporting Viewshare, and when it went offline on March 20 we moved to
The first In Progress Viewer was built in the Library of Congress’s Viewshare, which provided federated browsing for all the fields in our records, along with a timeline and simple mapping facility. Unfortunately the Library of Congress is no longer supporting Viewshare, and when it went offline on March 20 we moved to 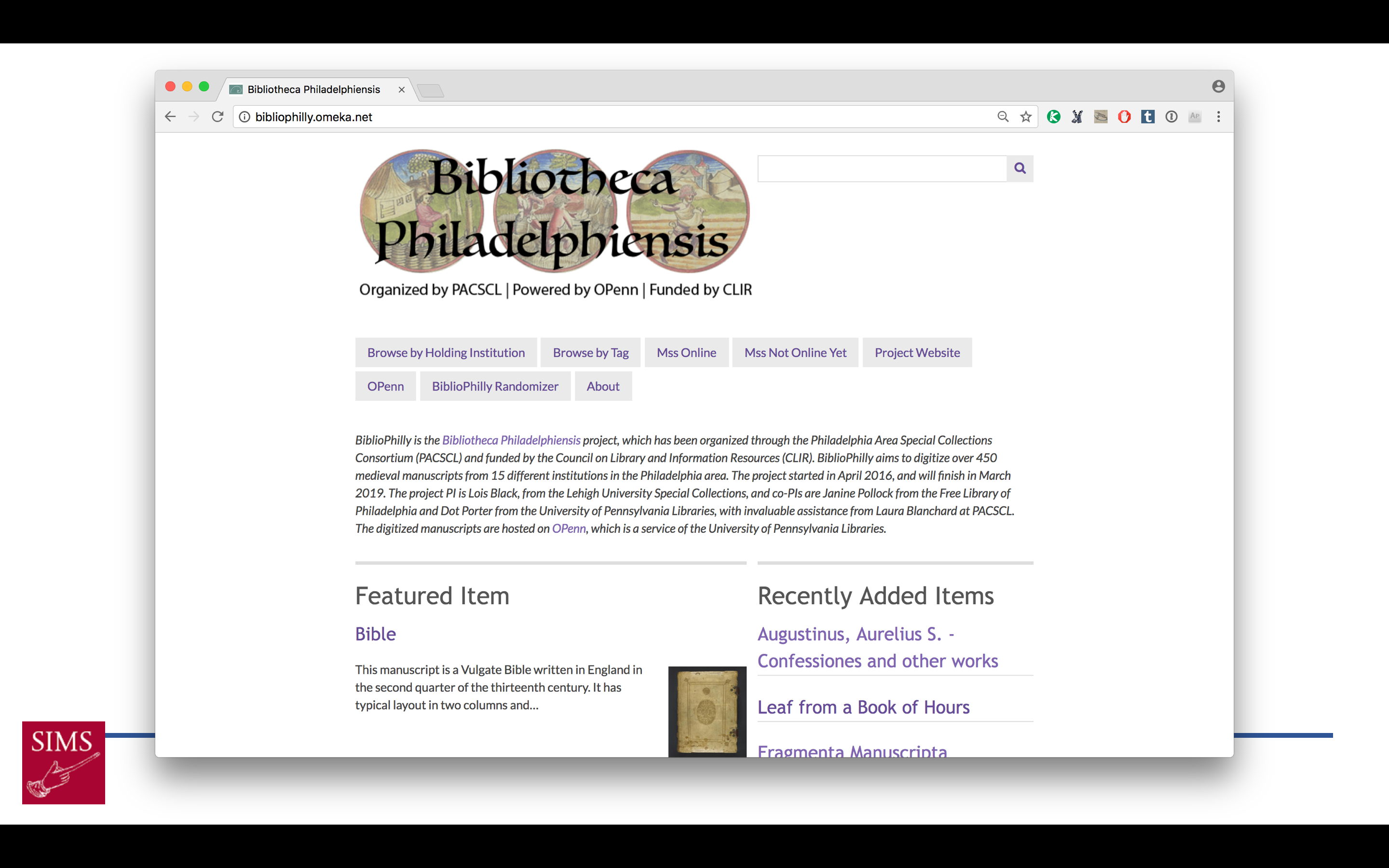 an Omeka platform, which is more attractive but lacks the federated searching that made Viewshare so compelling. From Omeka (and Viewshare before it) we link to the manuscript data on OPenn, to Internet Archive BookReader page-turners, and to VisColl collation views. Both the BookReaders and VisColl views are generated locally from scripts and hosted on a Digital Ocean droplet. This is a temporary system, and is not built to last beyond the end of the project. It will be replaced by an official, longer-lived interface.
an Omeka platform, which is more attractive but lacks the federated searching that made Viewshare so compelling. From Omeka (and Viewshare before it) we link to the manuscript data on OPenn, to Internet Archive BookReader page-turners, and to VisColl collation views. Both the BookReaders and VisColl views are generated locally from scripts and hosted on a Digital Ocean droplet. This is a temporary system, and is not built to last beyond the end of the project. It will be replaced by an official, longer-lived interface.
We’re also able to leverage the OPenn design of BiblioPhilly and VisColl for this “official” interface, which is currently under development with Byte Studios of Milwaukee, Wisconson. While our In Progress Viewer has both page-turning facility and collation views, those elements are separate and are not designed to interact. The interface that we are designing with Byte Studios incorporates the collation data with the page-turning and will allow a user to switch seamlessly between page openings and full sheets.
It’s exciting that we’ve been able to leverage what was essentially an audience-less platform into something that can so well serve its curator, but there is a question that this approachpushes wide open: What does it mean to be a curator? With a background in digital humanities focused on the development of editions of medieval manuscripts I was basically the perfect curator for OPenn. But that was a happy accident. Most special collections curators don’t have my background or my technical training, so access to something like OPenn wouldn’t help them, and I’m very hesitant to suggest that every curator be trained in programming. I do think that every special collections department should have some in-house digital expertise, and maybe that’s the direction to go. Anyway, I’m very happy being in my current situation and I only wish we’d considered the curator as an audience for OPenn earlier in the process.