
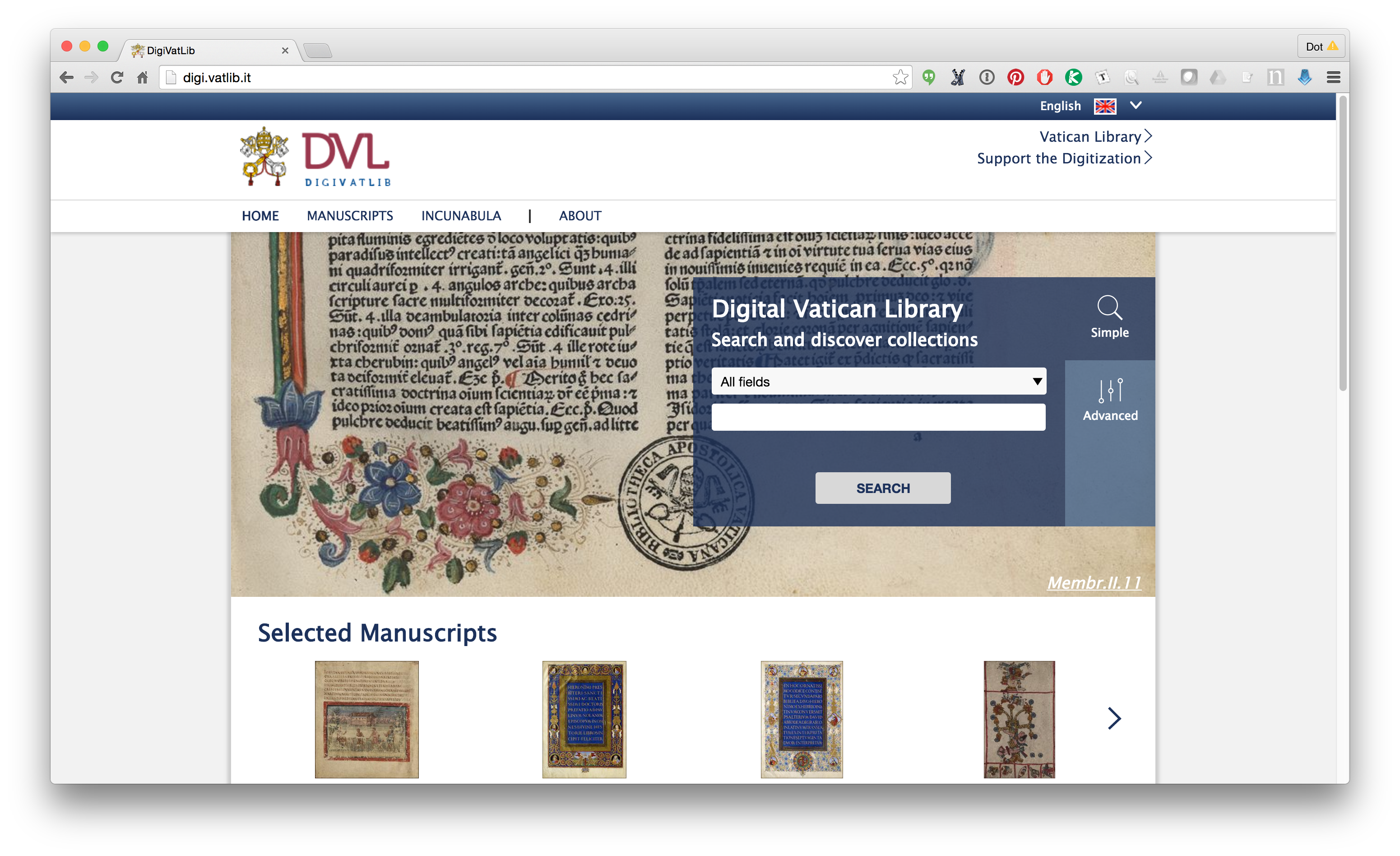
Last week I posted on how to use a Firefox plugin called Down them All to download all the files from an e-codices IIIF manifest (there’s also a tutorial video on YouTube, one of a small but growing collection that will soon include a video outlining the process described here), but not all manifests include direct links to images. The manifests published by the Vatican Digital Library are a good example of this. The URLs in manifests don’t link directly to images; you need to add criteria at the end of the URLs to hit the images. What can you do in that case? In that case, what you need to do it build a list of urls pointing to images, then you can use Down Them All (or other tools) to download them.
In addition to Down Them All I like to use a combination of TextWrangler and a website called Multilinkr, which takes text URLs and turns them into hot links. Why this is important will become clear momentarily.
Let’s go!
First, make sure you have all the software you’ll need: Firefox, Down Them All, and TextWrangler.
Next, we need to pull all the base URLs out of the Vatican manifest.
- Search the Vatican Digital Library for the manuscript you want. Once you’ve found one, download the IIIF manifest (click the “Bibliographic Information” button on the far left, which opens a menu, then click on the IIIF manifest link)

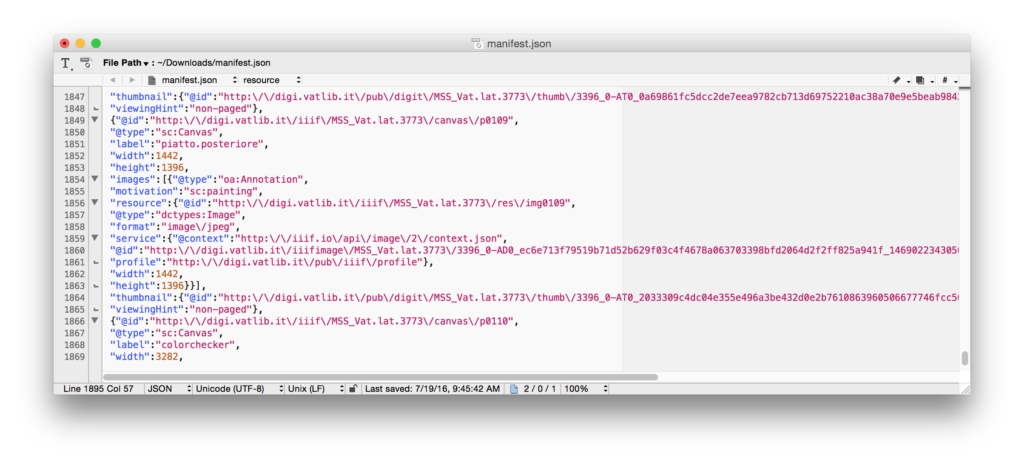
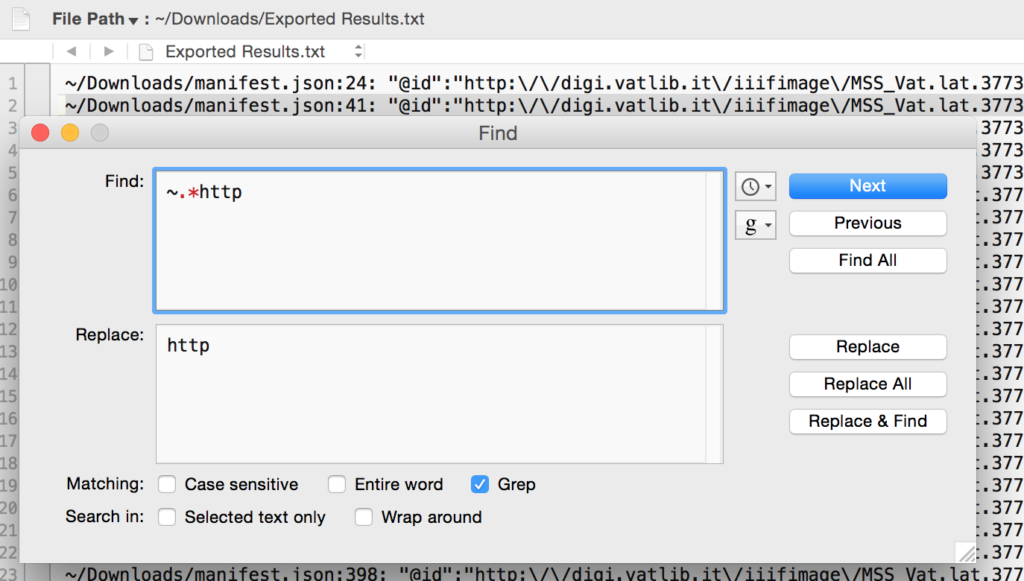
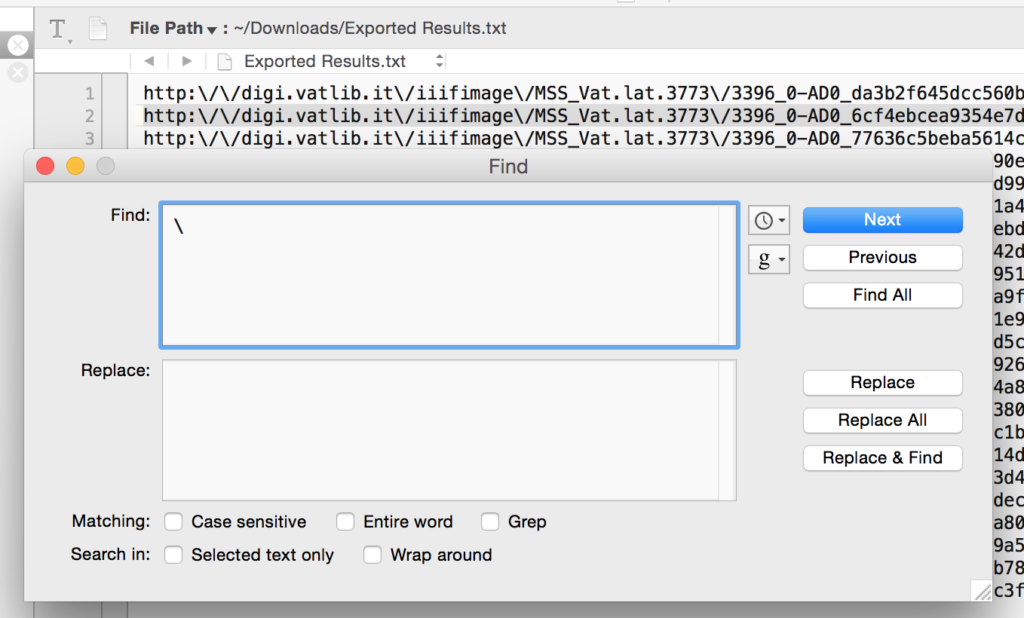
You need to get all the URLs on separate lines. The easiest way to do this is to find and replace all commas with a comma followed by a hard return. Do this using the “grep” option, using “\r” to add the return. Your find and replace box will look like this (don’t forget to check the “grep” box at the bottom!):
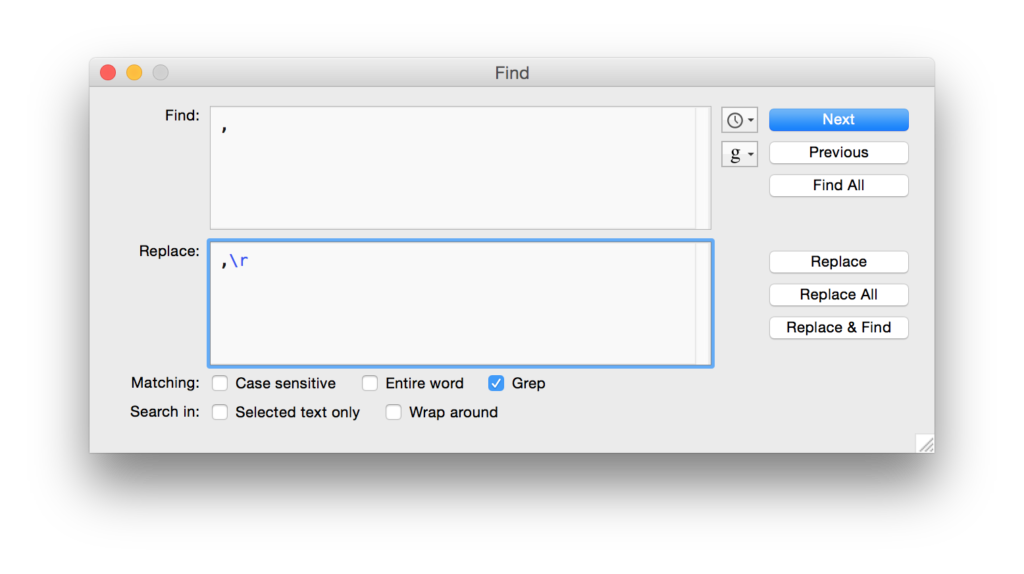
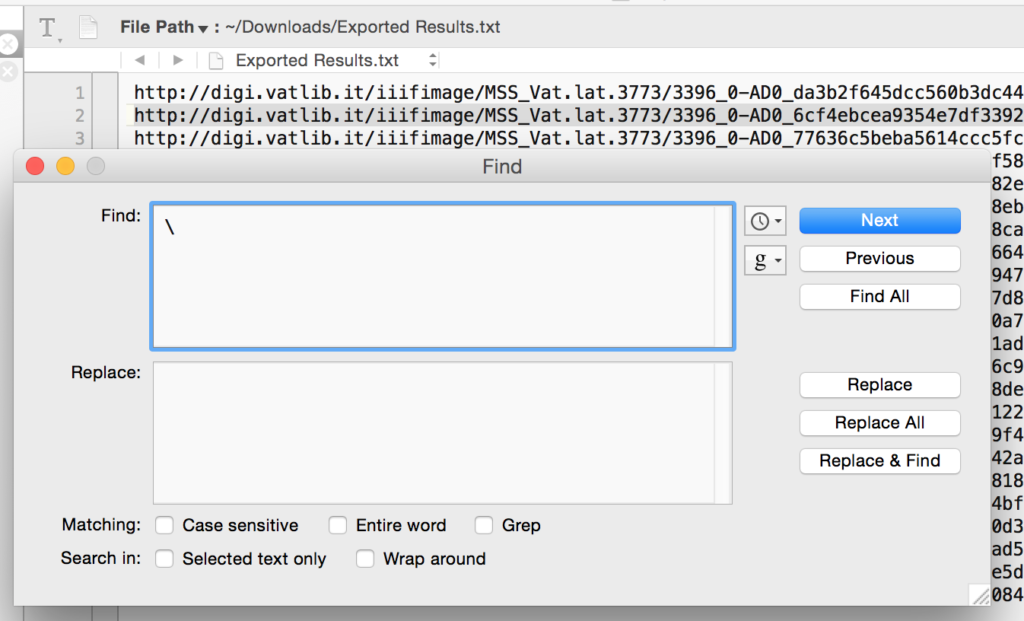
Your manifest will now look something like this:
Your results will appear in a new window, and will look something like this:
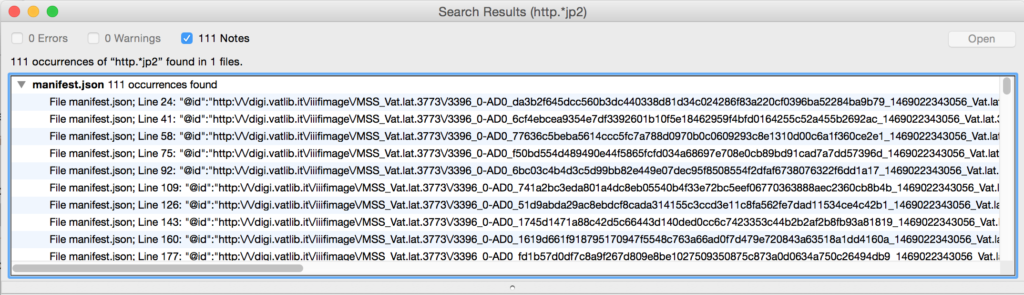
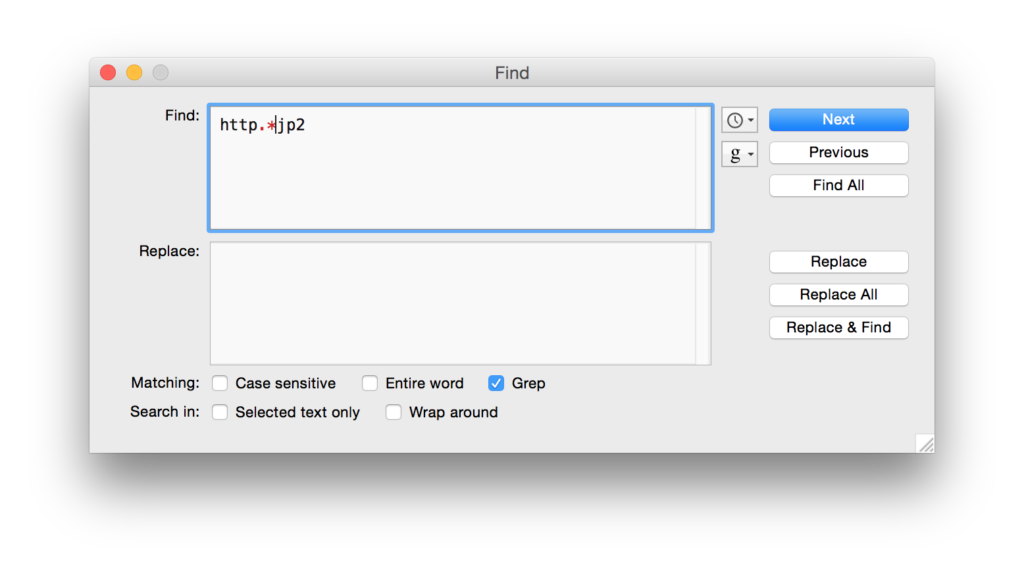
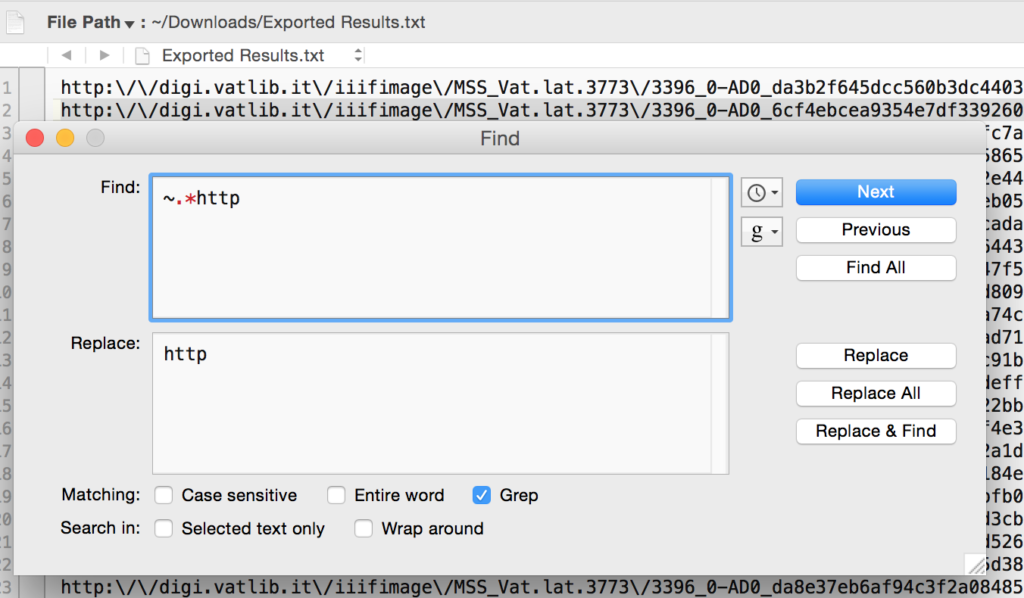
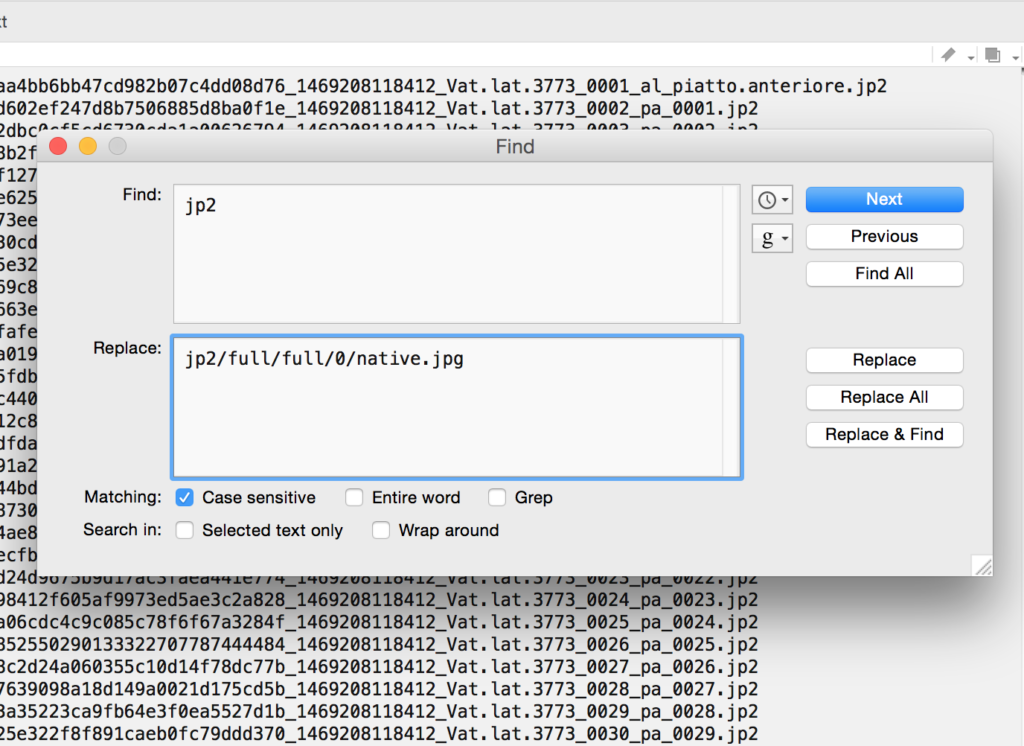
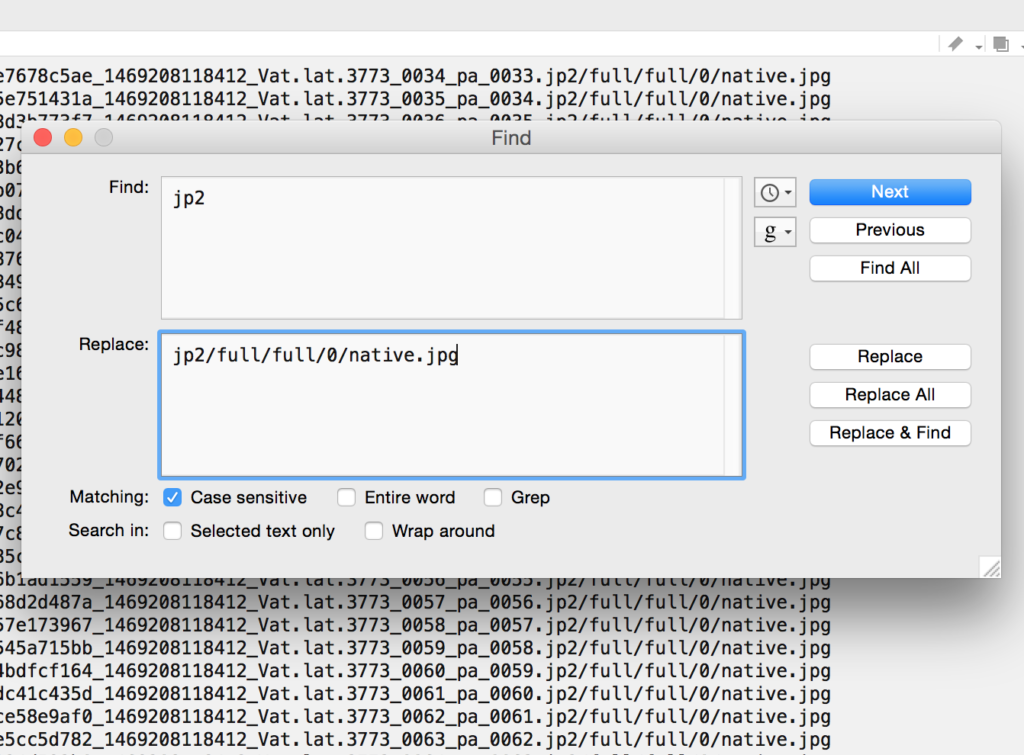
Save that text file wherever you’d like. Then open it in TextWrangler. You now need to do some finding and replacing, using “grep” (again!) and the .* regular expression to remove anything that is not http…jp2. I had to do two runs to get everything, first the stuff before the URLs, then the stuff after:
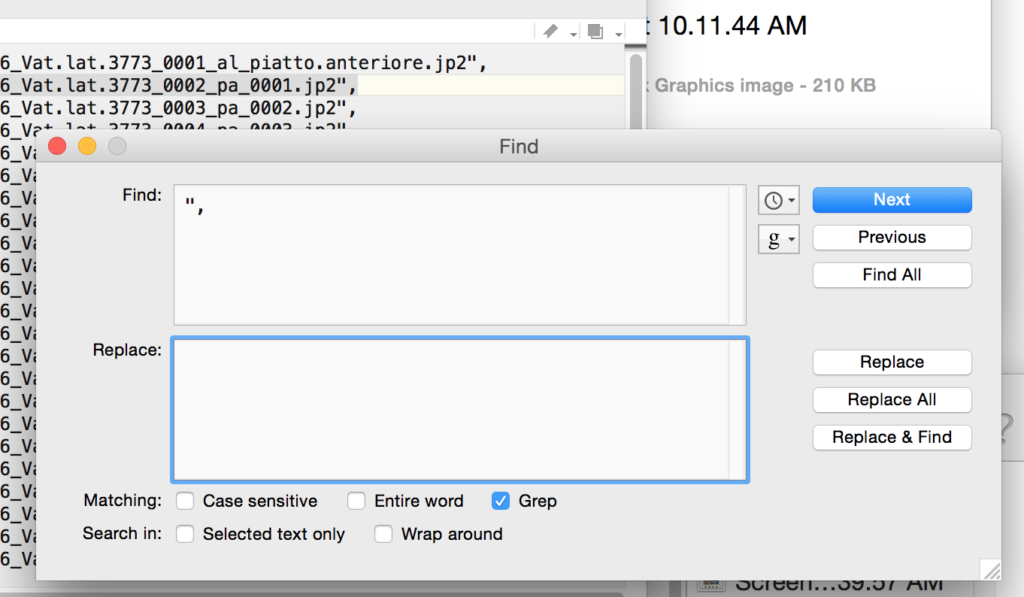
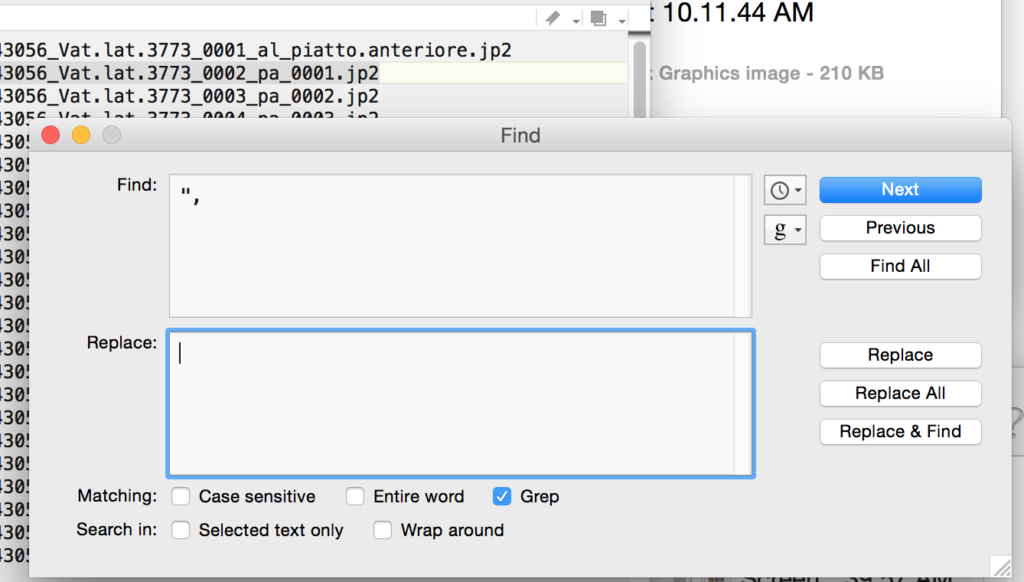
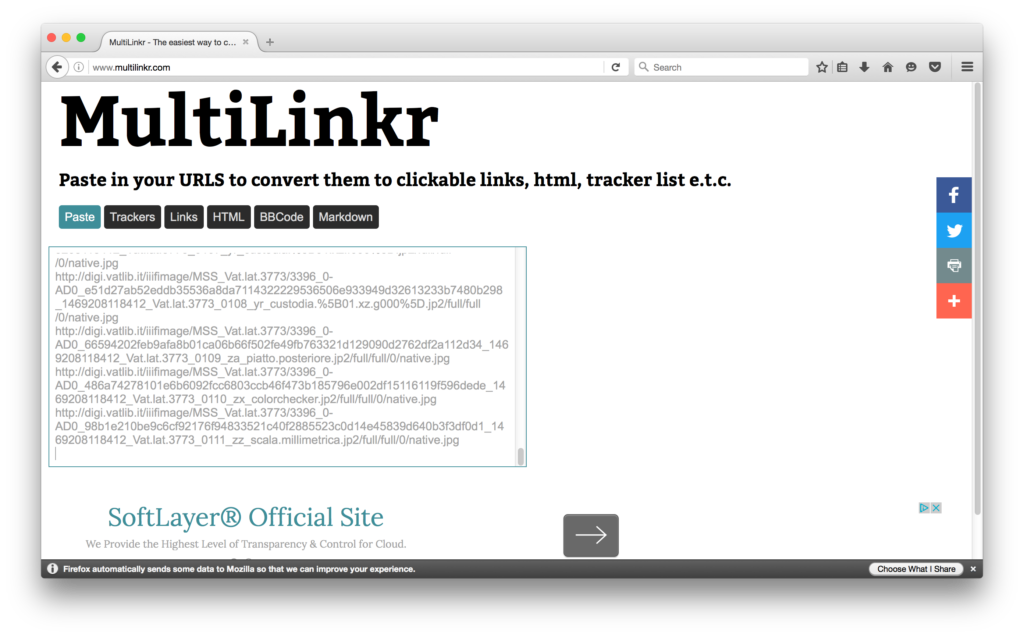
Hooray! We have our list of base URLs. Now we need to add the criteria necessary to turn these base URLs into direct links to images.
I keep mentioning the criteria required to turn these links from error-throwers to image files. If you go to the Vatican Digital Library website and mouse over the “Download” button for any image file, you’ll see what I mean. As you mouse that button over a bar will appear at the very bottom of your window, and if you look carefully you’ll see that the URL there is the base URL (ending in “jp2”) followed by four things separated by slashes:

There is a detailed description of what exactly these mean in the IIIF Image API Documentation on the IIIF website, but basically:
[baseurl]/region/size/rotation/quality
So in this case, we have the full region (the entire image, not a piece of it), size 1047 pixels across by however tall (since there is nothing after the comma), rotation of 0 degrees, and a quality native (aka default, I think – one could also use bitonal or gray to get those quality of images). I like to get the “full” image size, so what I’m going to add to the end of the URLS is:
[baseurl]/full/full/0/native.jpg
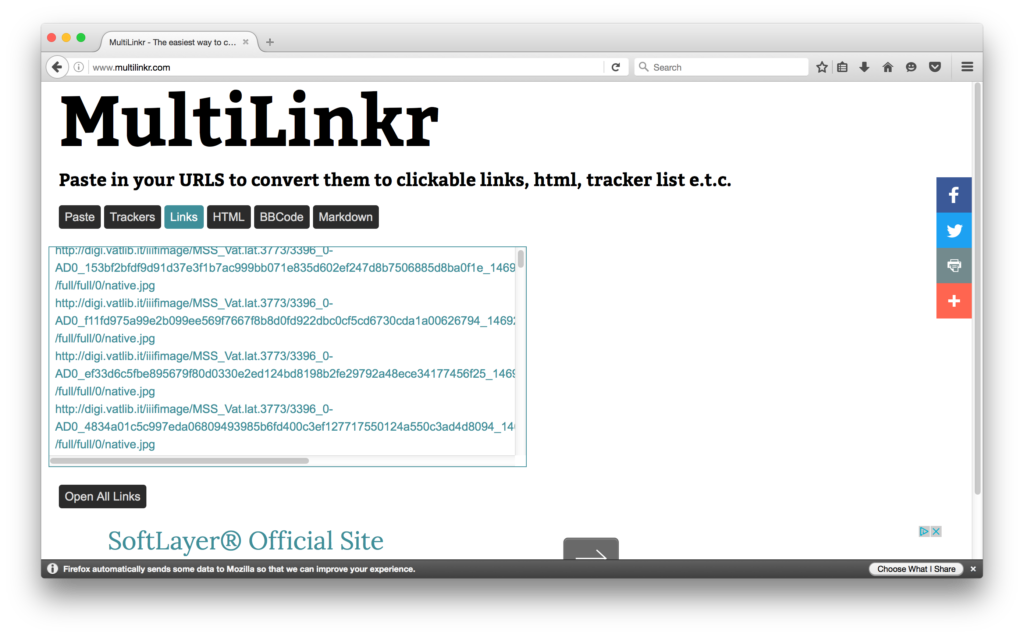
We’ll just do this using another find and replace in TextWrangler.
Test one, just to make sure it works. Copy and paste the URL into a browser.
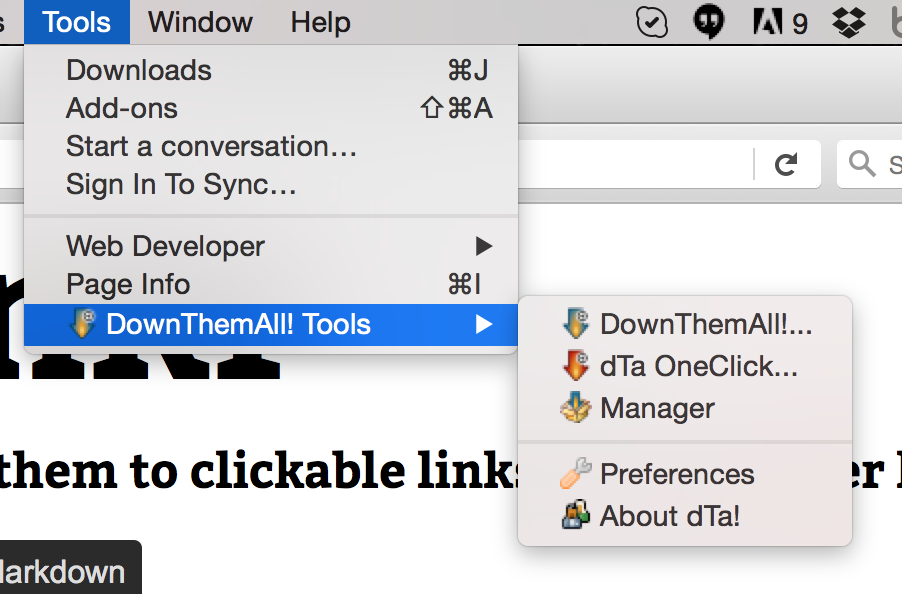
Now go up to the Firefox “Tools” menu and select “Down Them All Tools > Down Them All” from the dropdown: Down Them All should automatically recognize all the files and highlight them. Two things to be careful about here. One is that you need to specify a download location. It will default to your Downloads folder, but I like to indicate a new folder using the shelfmark of the manuscript I’m downloading. You can also browse to download the files wherever you’d like. The second one is that Down Them All will keep file names the same unless you tell it to do something different. In the case of the Vatican that’s not ideal, since all the files are named “native.jpg”, so if you don’t do something with the “Renaming Mask” you’ll end up with native.jpg native.jpg(1) native.jpg(2) etc. I like to change the Renaming Mask from the default *name*.*ext* to *flatsubdirs*.*ext* – “flatsubdirs” stands for “flat subdirectories”, and it means the downloaded files will be named according to the path of subdirectories wherever they are being downloaded from. In the case of the Vatican files, a file that lives here:
http://digi.vatlib.it/iiifimage/MSS_Vat.lat.3773/3396_0-AD0_f11fd975a99e2b099ee569f7667f8b8d0fd922dbc0cf5cd6730cda1a00626794_1469208118412_Vat.lat.3773_0003_pa_0002.jp2/full/full/0/native.jpg
will be renamed
iiifimage-MSS_Vat.lat.3773-3396_0-AD0_f11fd975a99e2b099ee569f7667f8b8d0fd922dbc0cf5cd6730cda1a00626794_1469208118412_Vat.lat.3773_0003_pa_0002.jp2-full-full-0.jpg
This is still a mouthful, but both the shelfmark (Vat.lat.3773) and the page number or folio number are there (here it’s pa_0002.jp2 = page 2, in other manuscripts you’ll see for example fr_0003r.jp2), so it’s simple enough to use Automator or another tool to batch rename the files by removing all the other bits and just leaving the shelfmark and folio or page number.
There are other ways you could do this, too, using Excel to construct the URLs and wget to download, but I think the method outlined here is relatively simple for people who don’t have strong coding skills. Don’t hesitate to ask if you have trouble or questions about this! And please remember that the Vatican manuscript images are not licensed for reuse, so only download them for your own scholarly work.
Hi there,
Let me share this other method which I think is easier. It’s very similar to the one used for GallicaBnF (https://medium.com/hackernoon/how-to-download-hi-res-images-from-museum-websites-b4446387e75d)
Once you are on the desired page (or fol.), you just need to find any of the “native” images by using the “inspect element” tool > sources > images > and select any of the “native.jpg” (which are the different parts of the puzzle).
Then you have to copy the URL of this native.jpg and replace the two long numbers before /0/ (which are the coordinates of the “piece of the puzzle” and the zoom level) with “full” in both cases. That gives you the full native.jpg of the whole page. This is an example:
-original URL of a random “native.jpg” from the “inspect element” tool: https://digi.vatlib.it/pub/digit/MSS_Vat.lat.5729/iiif/Vat.lat.5729_0328_fa_0162v.jp2/0,3072,1024,1024/512,/0/native.jpg
– replaced both numbers with “full”: https://digi.vatlib.it/pub/digit/MSS_Vat.lat.5729/iiif/Vat.lat.5729_0328_fa_0162v.jp2/full/full/0/native.jpg
Hope it helps.
Ignacio
Sorry for the very late reply, but this is great! Thank you for sharing.
Hello,
thanks a lot for this hacks. It helped to download some stuff from one archive. But there is one problem on that site. All images has embedded logo, sometimes it’s even not transparent (that’s horrible). So maybe someone knows if that logo could be embedded with IIIF, or it’s on original and there’s no way to remove it by changing “things” on URL? 🙂
Example:
https://eais.archyvai.lt/repo-ext/view/267816824
or direct image URL:
https://eais.archyvai.lt/iiif/2/102%2F266961949%2F267005383%2F267816824%2F268296913%2FPREVIEW_COPY%2F1%2FLVIA_PV_3003_13_3_0001.jp2/full/full/0/default.jpg
You see that awful LVK logo on the bottom right corner 🙁
Hi there,
Unfortunately it looks like that’s a watermark, which is part of the image file so there’s no way to remove it by changing the URL. You might google around to see if there are good methods for removing watermarks, but I have never done that. Sorry I can’t help with that but I’m glad the hacks are helpful!
dot
TextWrangler seems to be gone, and BBEdit is Mac only. You can use Notepad++ to do much the same editing. Once you have the manifest:
3. Search for all the lines with a url using Search|Find, the Find tab, “Find What” = “http.*jp2”, Wrap Around=ticked, Search mode=Regular expression and tap “Find All in Current Document”. The results all appear in a pane at the bottom. Copy that into a new document in Notepad++
4. Edit off the lines at top and bottom. Remove cruft at start of lines with Search|Replace, the Replacetab, “Find What” = “.*http”, Replace With= “http”, Wrap Around=ticked, Search mode=Regular expression and tap “Replace All”.
You could get rid of the trailing “,” with “Find What=””,” Replace With=”” in the same way. But I prefer to replace that with the rest of the url: “/full/full/0/native.jpg”
Once you have a text file with this stuff in, open the file with Firefox (by right-clicking on the file), and then open DownThemAll. Then carry on as above.