Following are my remarks from the Collections as Data National Forum 2 event held at the University of New Mexico, Las Vegas, on May 7 2018. Collections as Data is an Institute of Museum and Library Services supported effort that aims to foster a strategic approach to developing, describing, providing access to, and encouraging reuse of collections that support computationally-driven research and teaching in areas including but not limited to Digital Humanities, Public History, Digital History, data driven Journalism, Digital Social Science, and Digital Art History. The event was organized by Thomas Padilla, and I thank him for inviting me. It was a great event and I was honored to participate.
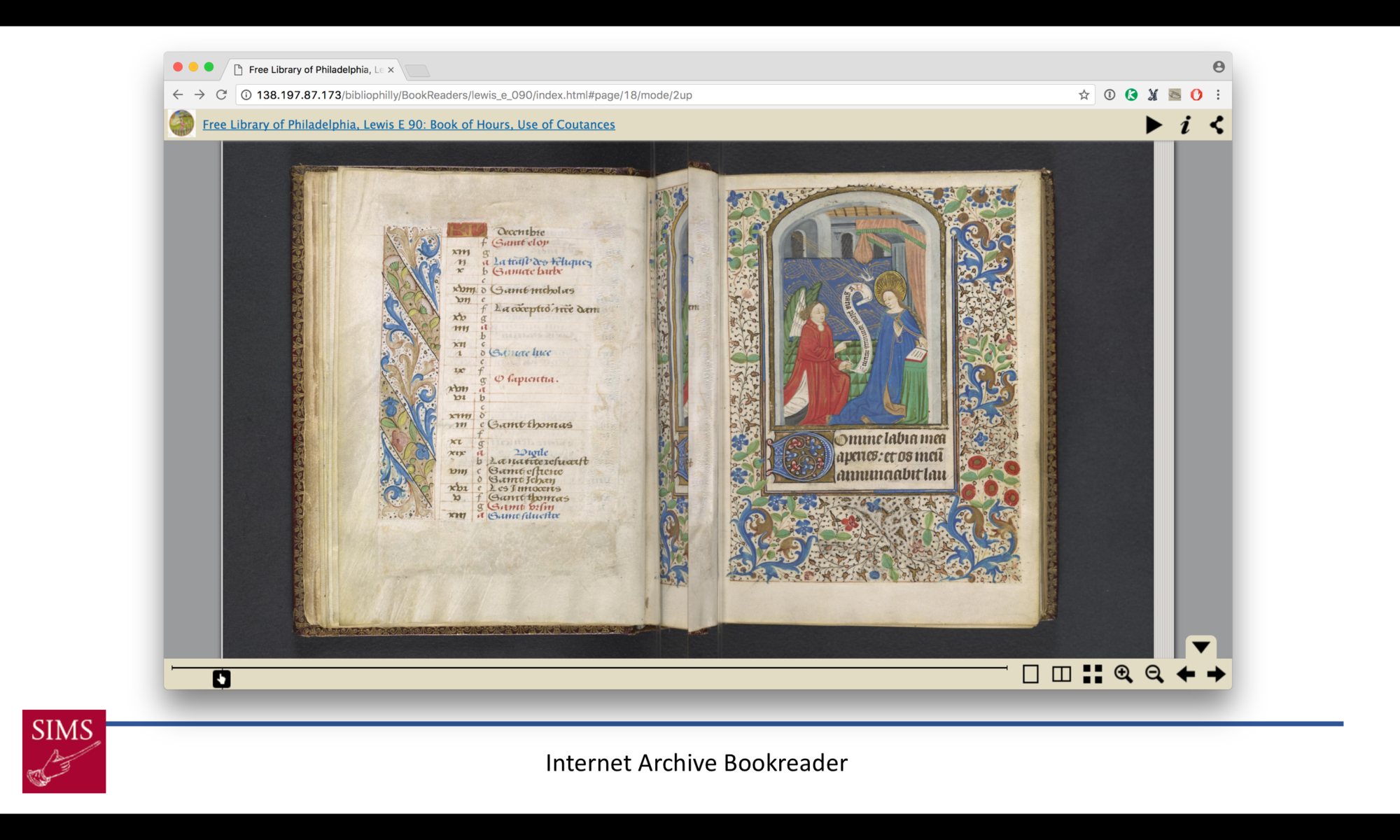
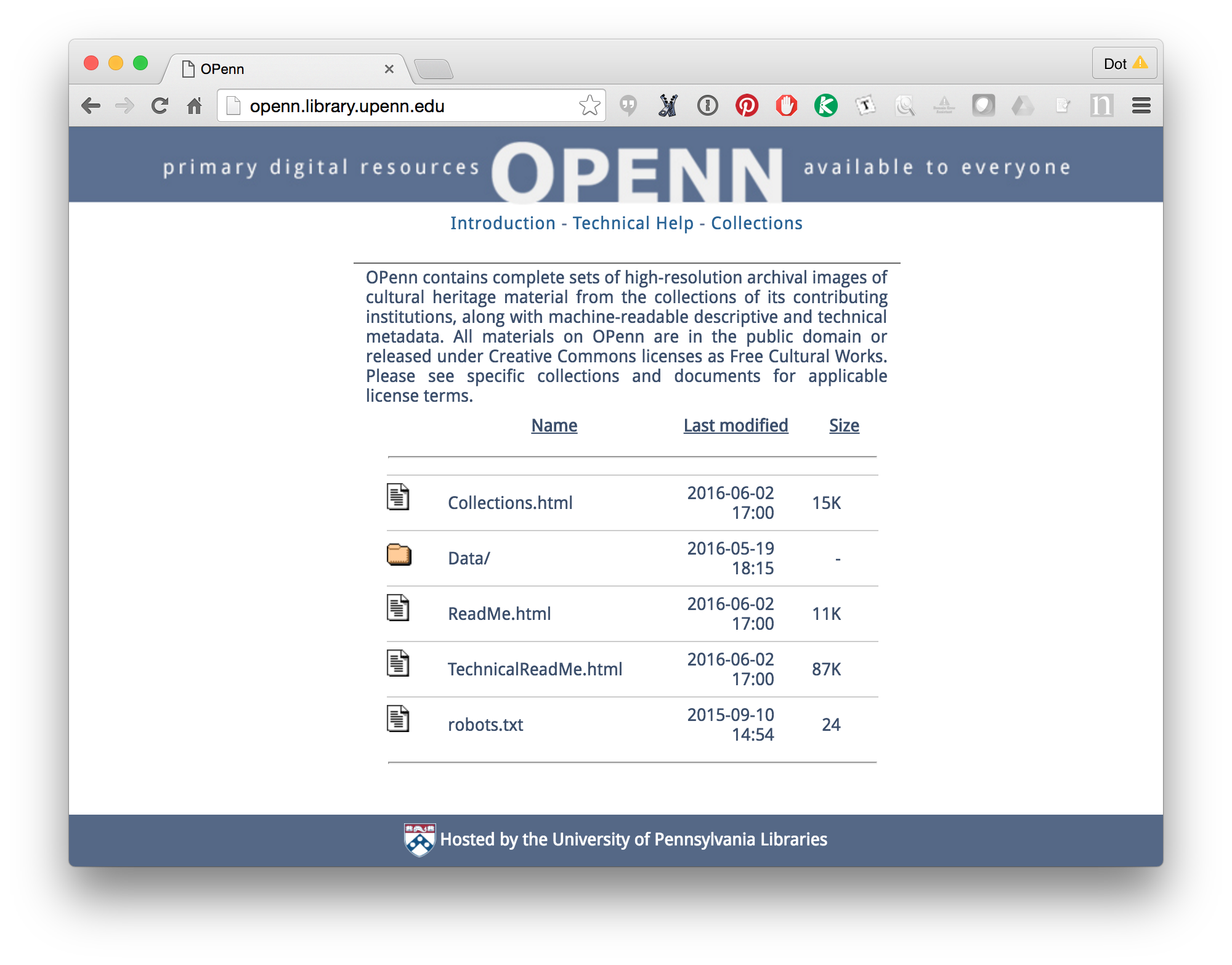
Continue reading “Data for Curators: OPenn and Bibliotheca Philadelphiensis as Use Cases”Data for Curators: OPenn and Bibliotheca Philadelphiensis as Use Cases